- content
开始前准备:强烈推荐使用 anaconda 来做 python 的环境管理工具,它里面自带了很多科学计算的类库,可以避免很多不必要的问题
显卡:我的显卡是 gtx960 最多只能训练10批次的数据,再多了显存就不足了,唉。。
下载图片
百度,谷歌都行,搜索一些图片,下载下来,放在 images 文件夹里,我这里用猫跟狗的图片来训练,我下载了40张图,20张猫,20张狗的图片
标记图片
下载labelimg工具,下载地址:https://github.com/tzutalin/labelImg
用法见readme里的介绍,标记好之后,图片文件夹里会生成跟图片数量相等的 xml 文件
然后在 images 文件夹里新建两个文件夹 train test 训练跟测试比例按照 4:1 来分一下刚才标记的图片,这个比例一般是 10:1 的比例,也就是10张训练图,1张测试的,我这图太少,就4:1来分了
注意:图片分开之后,原图还要在images文件夹里留着,也就是说,分图片的要用复制,不能用剪切,否则后面生成tfrecord文件的时候会报错
生成CSV
这一步将上一步标记图片生成的 xml 收集起来生成一个 csv 文件
打开 raccoon_dataset 项目,将里面的 xml_to_csv.py 文件复制出来,打开修改里面的内容如下:
这时候可以再创建一个文件夹 cat_dog 将 images 文件夹复制进去,然后将 xml_to_csv.py 保存在 cat_dog 文件夹里,再在 cat_dog 文件夹里创建一个 data 的文件夹用来放生成的 csv 文件
# 将下面这部分
def main():
image_path = os.path.join(os.getcwd(), 'annotations')
xml_df = xml_to_csv(image_path)
xml_df.to_csv('raccoon_labels.csv', index=None)
print('Successfully converted xml to csv.')
# 修改成下面这样
def main():
for directory in ['train', 'test']:
image_path = os.path.join(os.getcwd(), 'images/{}'.format(directory))
xml_df = xml_to_csv(image_path)
xml_df.to_csv('data/{}_labels.csv'.format(directory), index=None)
print('Successfully converted xml to csv.')
开启一个终端,你可以用cmd,powershell,或者直接在 anaconda 的 navigator 里启动一个自己创建好环境的终端,我这里用的是git bash
- 创建一个python版本为3.5的环境
conda create -n tf python=3.5 - 进入到创建的这个python3.5的环境里
source activate tf - 运行命令生成csv文件
python xml_to_csv.py
成功后,终端里会输出下面信息
$ python xml_to_csv.py
Successfully converted xml to csv.
Successfully converted xml to csv.
(tf)
生成tfrecord文件
还是 raccoon_dataset 项目,将里面的 generate_tfrecord.py 文件拷贝到 cat_dog 文件夹下,并修改内容如下
# 将下面内容
# TO-DO replace this with label map
def class_text_to_int(row_label):
if row_label == 'raccoon':
return 1
else:
None
# 修改成下面这样
# TO-DO replace this with label map
def class_text_to_int(row_label):
if row_label == 'cat':
return 1
elif row_label == 'dog':
return 2
else:
None
然后运行下面两条命令,生成 train.tfrecord test.tfrecord 两个文件,成功的话,终端里会输出下面信息
$ python generate_tfrecord.py --csv_input=data/train_labels.csv --output_path=data/train.record
Successfully created the TFRecords: C:\Users\liygh\Desktop\cat_dog\data\train.record
(tf)
liygh@DESKTOP-DI1356Q MINGW64 ~/Desktop/cat_dog
$ python generate_tfrecord.py --csv_input=data/test_labels.csv --output_path=data/test.record
Successfully created the TFRecords: C:\Users\liygh\Desktop\cat_dog\data\test.record
(tf)
安装model
下载 tensorflow 组织下的 models 项目 https://github.com/tensorflow/models 不嫌卡的可以 git clone 嫌卡的,直接下载zip包就可以了
下载下来解压,我这里放在桌面上了
然后下载一个 protobuf ,下面要用到 protoc 命令,下载地址: https://github.com/protocolbuffers/protobuf/releases 解压,配置环境变量,这里就跳过了
在终端里运行 protoc --version 命令,如果有输出 版本信息,就安装好了
PS: 如果环境变量配置好了,要把终端退了,再重新打开一下终端,它才会加载刚配置的环境变量,注意要再运行一次 source activate tf 进入tf环境
下面在终端里进入到 models-master/research 目录里运行命令来编译:protoc object_detection/protos/*.proto --python_out=.
然后添加类库到 PYTHONPATH 环境变量里, 还是在 research 目录下运行
export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim
遗憾的是 windows 上这样还是不行的,还要运行下面两条命令
- 在
research目录下运行python setup.py install - 在
research/slim目录下运行python setup.py build然后运行python setup.py install
下载训练的配置文件
下载文件 ssd_mobilenet_v1_pets.config 和 下载训练模式 ssd_mobilenet_v1_coco
其中 ssd_mobilenet_v1_pets.config 地址:https://github.com/tensorflow/models/blob/master/research/object_detection/samples/configs/ssd_mobilenet_v1_pets.config
ssd_mobilenet_v1_coco 地址: https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/detection_model_zoo.md
将下载的 ssd_mobilenet_v1_pets.config 和解压后的 ssd_mobilenet_v1_coco 都放在前面创建的 cat_dog 文件夹里
修改 ssd_mobilenet_v1_pets.config 文件的内容
# 找到
num_classes: 37
# 将其修改成 2 , 我这里就两个分类,猫跟狗
# 找到
num_steps: 200000
# 这个是训练步数,默认给的是20万步,我这改成 2000 步,你可以根据自己的需求来修改
num_steps: 2000
# 找到
fine_tune_checkpoint: "PATH_TO_BE_CONFIGURED/model.ckpt"
# 修改为
fine_tune_checkpoint: "ssd_mobilenet_v1_coco_2018_01_28/model.ckpt"
# 找到
train_input_reader: {
tf_record_input_reader {
input_path: "PATH_TO_BE_CONFIGURED/pet_faces_train.record-?????-of-00010"
}
label_map_path: "PATH_TO_BE_CONFIGURED/pet_label_map.pbtxt"
}
# 修改为
train_input_reader: {
tf_record_input_reader {
input_path: "data/train.record"
}
label_map_path: "data/object-detection.pbtxt"
}
# 找到
eval_input_reader: {
tf_record_input_reader {
input_path: "PATH_TO_BE_CONFIGURED/pet_faces_val.record-?????-of-00010"
}
label_map_path: "PATH_TO_BE_CONFIGURED/pet_label_map.pbtxt"
shuffle: false
num_readers: 1
}
# 修改为
eval_input_reader: {
tf_record_input_reader {
input_path: "data/test.record"
}
label_map_path: "data/object-detection.pbtxt"
shuffle: false
num_readers: 1
}
下面在 data 文件夹下创建 object-detection.pbtxt 文件, 填上下面内容
item {
id: 1
name: 'cat'
}
item {
id: 2
name: 'dog'
}
拷贝文件
将 cat_dog 文件夹下的 data images ssd_mobilenet_v1_pets.config ssd_mobilenet_v1_coco_2018_01_28 都复制到下载的 models 文件夹下 ,具体路径是 models-master/research/object_detection 下面
然后在 object-detection 文件夹下新建一个文件夹 training 用来存放训练结果的
开始训练
运行命令:python legacy/train.py --logtostderr --train_dir=training/ --pipeline_config_path=ssd_mobilenet_v1_pets.config 开始训练
如果是linux系统,安装了显卡想用显卡训练,还要加上下面配置
在 legacy/train.py 文件上面加上这段代码 os.environ["CUDA_VISIBLE_DEVICES"] = "0" 如果你只有一个显卡这里就是0,如果有两个显卡,可以指定使用第0块还是第1块,如果想两个都想用来训练,可以写成 os.environ["CUDA_VISIBLE_DEVICES"] = "0,1"
过程如下, 我的显卡是 gtx960 大概是 1.5s/step
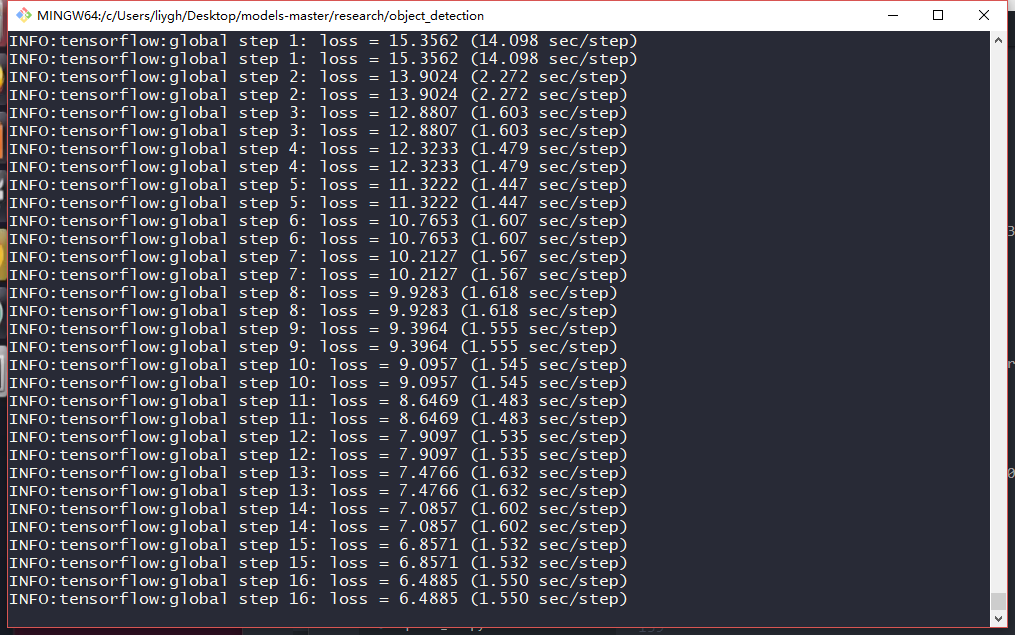
识别过程中,可以查看训练日志等信息,运行命令 tensorboard --logdir=training/ 然后浏览器运行 http://localhost:6006 就可以查看了
导出模型工具
运行下面命令将训练结果导出一个用来识别图片的工具,在cat_dog_graph文件夹里
python export_inference_graph.py \
--input_type image_tensor \
--pipeline_config_path ssd_mobilenet_v1_pets.config \
--trained_checkpoint_prefix training/model.ckpt-2000 \
--output_directory cat_dog_graph
识别图片
再下载几张猫狗的图片,命名为 image{数字}.jpg 放在 object-detection 下的 test_images 文件夹下

在 object-detection 文件夹下运行命令 jupyter notebook 在自动打开的浏览器页面里打开 object_detection_tutorial.ipynb 文件并进行如下修改
# 找到
MODEL_NAME = 'ssd_mobilenet_v1_coco_2017_11_17'
# 修改为
MODEL_NAME = 'cat_dog_graph'
# 删除下面两行
MODEL_FILE = MODEL_NAME + '.tar.gz'
DOWNLOAD_BASE = 'http://download.tensorflow.org/models/object_detection/'
# 找到
PATH_TO_LABELS = os.path.join('data', 'mscoco_label_map.pbtxt')
# 修改为
PATH_TO_LABELS = os.path.join('data', 'object-detection.pbtxt')
# 找到
NUM_CLASSES = 90
# 修改为
NUM_CLASSES = 2
# 找到下面内容然后全部注释掉
opener = urllib.request.URLopener()
opener.retrieve(DOWNLOAD_BASE + MODEL_FILE, MODEL_FILE)
tar_file = tarfile.open(MODEL_FILE)
for file in tar_file.getmembers():
file_name = os.path.basename(file.name)
if 'frozen_inference_graph.pb' in file_name:
tar_file.extract(file, os.getcwd())
# 找到
TEST_IMAGE_PATHS = [ os.path.join(PATH_TO_TEST_IMAGES_DIR, 'image{}.jpg'.format(i)) for i in range(1, 3) ]
# 修改为
TEST_IMAGE_PATHS = [ os.path.join(PATH_TO_TEST_IMAGES_DIR, 'image{}.jpg'.format(i)) for i in range(1, 8) ]
然后在jupyter里运行这个文件,等待片刻即可看到识别的效果
